
Que ce soit pour enrichir un dossier documentaire, ou pour mettre en place une veille sur un sujet, les professionnels de l’infodoc ont régulièrement besoin d’identifier des sources pertinentes.
Pour ce faire, le premier réflexe est alors, majoritairement, de lancer une recherche sur Google avec quelques mots, puis d’analyser les résultats et d’affiner les termes de sa requête, jusqu’au repérage de sources intéressantes.
Si cette démarche s’avère le plus souvent fructueuse, elle peut néanmoins être utilement complétée par des recherches tirant parti de certaines fonctionnalités propres à Google, et par l’exploration de sources et d’outils du Web social.
Nous illustrerons quelques pistes en partant d’un cas concret : “identifier des ressources sur la gestion des déchets”.
Cette thématique servira de prétexte à nos remarques concernant le fonctionnement de Google, et à la présentation de quelques pistes d’exploration.
En revanche, la phase de réflexion sur le choix des mots-clés ne sera pas abordée ici.
HAUT
Google : quelques précisions
Une recherche sur Google avec les termes gestion déchets annonce 16,2 millions de résultats.
Mais en fait, comme nous avons déjà eu l’occasion de l’expliquer dans ces colonnes (lire notamment “Enquêtes autour de la taille des moteurs”, Netsources n°57, juillet-août 2005), ces chiffres sont totalement approximatifs.
Dans notre cas par exemple, seules 488 réponses sont ainsi affichées de prime abord ; si l’on veut obtenir les 1000 résultats auxquels on a théoriquement droit, il faut cliquer sur le lien “relancer la recherche pour inclure les résultats omis”, proposé en dernière page…
Pour vérifier le nombre de résultats réellement proposé, mais surtout pour analyser plus aisément la pertinence des réponses, nous conseillerons de modifier les paramètres de Google pour choisir l’affichage de 100 résultats par page (et non 10, par défaut) ; il est en effet plus simple de survoler les réponses en scrollant l’ascenseur, que de cliquer systématiquement sur “Page suivante”…
Pour ce faire, il faut tout d’abord cliquer sur le choix “Paramètres de recherche” accessible via la roue dentée (en haut à droite de la page de résultats).
On doit alors désactiver l’option “Prédictions de la recherche instantanée”, puis faire glisser le curseur jusqu’à 100 résultats par page (voir écran ci-contre), et enfin enregistrer ses préférences, pour les retrouver lors de recherches ultérieures.
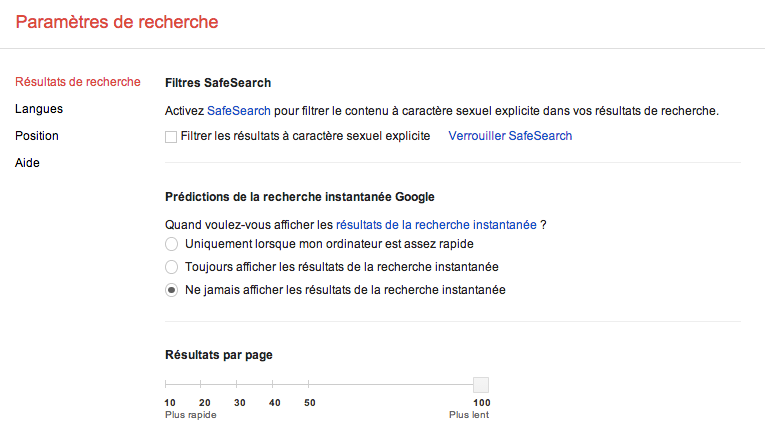
Paramétrage du nombre de résultats par page
Quel que soit le paramétrage choisi, la requête gestion déchets affiche, parmi les premières réponses :
- l’incontournable Wikipedia
- des sites institutionnels (ministère du Développement durable, Ademe, Andra…)
- des actualités correspondant à la thématique
- des sites d’entreprise (Veolia…)
- des sites généralistes sur l’environnement (Notre Planete Info…)
- des sites de collectivités.
L’analyse des résultats confirme que Google personnalise de plus en plus souvent les réponses.
Même si l’on prend garde d’effectuer la recherche sans être logué avec son compte Google, on obtient en effet dans les premières pages des sources sélectionnées en fonction de son emplacement géographique, repéré automatiquement grâce à l’adresse IP de son ordinateur.
Lors de nos tests par exemple, nous avions ainsi en 10ème position la page “Gestion des déchets et propreté” du site officiel de la ville de Saint Maur des Fossés, d’où étaient effectuées les recherches…
Il est possible d’éviter, en partie, cette personnalisation, en cliquant sur l’onglet “Outils de recherche” de la barre d’outils proposée en haut de la page.
Un clic sur cet onglet fait apparaître une deuxième série d’onglets, parmi lesquels on trouve, à l’extrême droite, celui relatif à la position géographique.
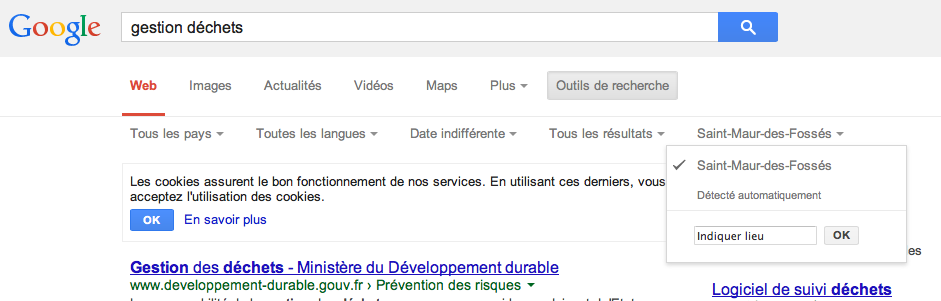
Onglet « Outils de recherche » puis menu « Localisation »
Si Google indique par défaut la localisation géographique de l’ordinateur, on peut choisir un autre emplacement, en saisissant une ville, ou un pays (France).
La ville indiquée doit toutefois être située dans le pays de l’interface Google interrogée (France pour Google.fr, etc).
Par conséquent, si l’on souhaite par exemple identifier des résultats situés à proximité de Lisbonne, il faudra se connecter à Google.pt, lancer une recherche et modifier la localisation en cliquant sur “Outils de recherche”…
L’accès à Google.com quant à lui se fait directement depuis le lien Google.com, proposé en bas de l’écran d’accueil de Google.Mais il est impératif d’être déconnecté de son compte Google.
Il est malheureusement impossible de désactiver totalement cette localisation géographique, sauf à utiliser un outil d’anonymisation…
Quelle que soit la recherche effectuée, le survol rapide des réponses obtenues permet de vérifier relativement aisément la pertinence des mots-clés choisis, et la façon dont Google les a interprétés.
Il faut en effet être conscient que Google “interprète” les questions de plus en plus systématiquement – et de façon de plus en plus large –, et ne se contente pas de rechercher les mots tels qu’ils sont écrits.
Cette interprétation s’avère généralement utile, car elle se traduit le plus souvent par une recherche sur les formes voisines des termes (pluriel/singulier…) ou par la prise en compte de synonymes. Cela étant, on prendra garde au fait qu’il ne s’agit nullement d’une règle, et que les termes sont quelquefois recherchés de façon stricte.
D’autre part, et c’est plus fâcheux, il arrive que “l’interprétation” de Google se traduise par la prise en compte de termes “proches” mais non pertinents (bibliographie “jean racine” identifie ainsi les pages contenant biographie “jean racine”), voire par la suppression de certains termes de la requête, lorsque le moteur “le juge utile” (voir “Les approximations de Google”, Netsources n°74).
On peut heureusement “forcer” la recherche sur les mots tels qu’ils sont écrits, en saisissant chaque terme (ou du moins ceux qui ont été “oubliés” par Google) entre guillemets, ou en choisissant l’option “Mot à Mot”, via les onglets “Outils de Recherche” puis “Tous les résultats”.
Mais dans ces deux cas, les formes voisines des mots ne seront pas recherchées et il faudra penser à les inscrire en les reliant avec OR…
Après avoir lancé sa requête sur Google, le premier réflexe d’un professionnel doit donc être de vérifier la façon donc le moteur a interprété la question – c’est là que les 100 réponses par page trouvent leur justification –, puis d’ajuster, le cas échéant, sa requête.
Cette première étape d’une recherche par mots-clés permet en règle générale d’identifier un certain nombre de ressources.
Mais lorsque l’on souhaite sélectionner une liste de sites (et non directement les pages contenant la réponse à la question), le process s’avère long et fastidieux, car les sources de référence sont noyées au milieu de pages qui, si elles concernent bien le sujet, sont issues de sites plus généralistes (site d’actualité, Wikipedia…).
Dans un tel cas, il et plus sage et plus efficace de démarrer sa prospection en essayant d’identifier directement une “page de liens”, autrement dit une sélection de sites sur le sujet qu’un expert, un passionné ou une association aura déjà réalisée et mise à disposition sur le Net. Nous avons plusieurs fois eu recours à ces outils pour répondre à des questions spécifiques (voir Netsources n°91 et n°82).[/column]
HAUT
Etoffer son sourcing en identifiant des pages de liens
Les “pages de liens”, que l’on nomme également “signets” ou “bookmarks”, se présentent fréquemment sous la forme d’une collection de liens hypertexte sur un sujet, avec une description succincte de chaque site.
Elles font quelquefois partie intégrante d’un site beaucoup plus large (site institutionnel, associatif…), disposant d’une rubrique “Liens utiles”, ou sont le résultat d’un travail personnel – celui d’un étudiant, d’un expert, ou d’un passionné par exemple –, qui aura décidé de mettre à disposition de tous les résultats de sa recherche.
Il existe des pages de liens sur à peu près tous les domaines, du plus généraliste au plus spécialisé.
Si ces ressources ont leurs limites – leur couverture ne sera pas exactement celle que l’on souhaite, leur mise à jour est souvent aléatoire, etc.–, elles font néanmoins gagner un temps précieux dès lors que l’on est à la recherche d’une liste de sites.
Pour identifier ces pages de liens, nous avons élaboré une méthode (ou plutôt une astuce) qui s’appuie sur une constatation : les pages de liens proposées sur les sites sont très souvent incluses dans une rubrique intitulée simplement « Liens utiles », « Sites du domaine », etc.
Un clic sur cette rubrique affiche la page en question et il arrive alors que celle-ci contienne, dans son titre ou son URL, le mot “liens” ou “sites”, “bookmark”, etc.
Bien évidemment, la présence du mot « liens » dans le titre ou dans l’URL n’est pas obligatoire. Il se trouve simplement que de nombreux éditeurs choisissent ce mot comme titre de leur page ou que le chaînage de navigation dans leur site explique la présence du terme dans l’URL.
Partant de cette constatation, on utilisera les fonctions avancées de Google pour rechercher les pages qui contiennent précisément le ou les termes de la requête ET le mot liens (ou sites, bookmark, ressources…) dans le titre OU dans l’URL.
Si l’on souhaite identifier des pages en anglais, on pensera à utiliser les mots links (ou bookmark, resources, sites…) en complément des mots-clés.
Dans notre cas, cela revient à chercher sur Google les pages qui contiennent à la fois :
- les mots gestion déchets dans le texte ; on peut aussi affiner la requête en précisant le type de sites que l’on recherche, pour identifier par exemple spécifiquement des sites d’associations…
- le mot liens ou sites dans le titre (opérateur intitle:) ou dans l’URL (opérateur inurl:).
La requête pourra donc être formulée comme suit :
gestion déchets associations intitle:liens OR intitle:sites OR inurl:liens OR inurl:sites.
On prendra particulièrement garde à bien saisir un OR entre les synonymes (liens ou sites, dans le titre ou dans l’URL), et à avoir un espace (donc un AND implicite) entre cet ensemble et les mots concernant la thématique (gestion déchets…).
D’autre part, la saisie des différents synonymes dans le titre et l’URL étant fastidieuse (il faut répéter à chaque fois l’opérateur intitle: ou inurl: devant chaque mot), on préférera l’usage de l’opérateur « | » (prononcer « pipe ») à OR, ce qui permet de poser la requête sous la forme :
gestion déchets associations intitle:liens|sites OR inurl:liens|sites.
L’opérateur “|” s’obtient avec les touches maj+alt+L sur Mac, et ctrl+alt+6 sur PC ; il ne doit pas y avoir d’espace entre l’opérateur intitle:, les mots-clés et le |.
Cette requête affiche de nombreux résultats pertinents, parmi lesquels on trouve, par exemple, une page de liens utiles fournie par le Cniid (Centre national d’information indépendante sur le déchets) ; cette page recense plus de soixante sites classés par type (outils, associations françaises, locales, dédiées à la “décharge”, au “compostage”, associations étrangères, sites officiels, etc.), et propose pour chaque site une brève description.

HAUT
Intégrer le Web social dans sa veille
En quelques années, les modes de consommation de l’information ont radicalement changé. Les outils du Web social notamment ont fait une montée en puissance indéniable, et ne peuvent à ce titre être exclus du processus de recherche d’information et de veille.
Outre les classiques moteurs de recherche, différents types de ressources sont aujourd’hui susceptibles d’apporter des compléments précieux dans l’élaboration d’un sourcing ; on compte notamment parmi eux des réseaux sociaux – comme Twitter, Google+, mais aussi Linkedin ou Viadeo – et des plateformes de curation (Scoop.it, Pearltrees…).
A titre d’illustration, on trouvera ci-après quelques exemples de recherches sur ces outils du Web social…
Pearltrees
Lancé en 2009, Pearltrees permet aux internautes de conserver, d’organiser et de retrouver des contenus web, classés sour la forme d’un arbre de perles (chaque perle symbolisant un lien, voir Netsources n°84).
A mi-chemin entre le site de social bookmarking et la plateforme de curation, l’outil permet aisément d’étoffer un sourcing, puisqu’il propose en fait l’équivalent “2.0” des “pages de liens”, présentées sous forme visuelle.
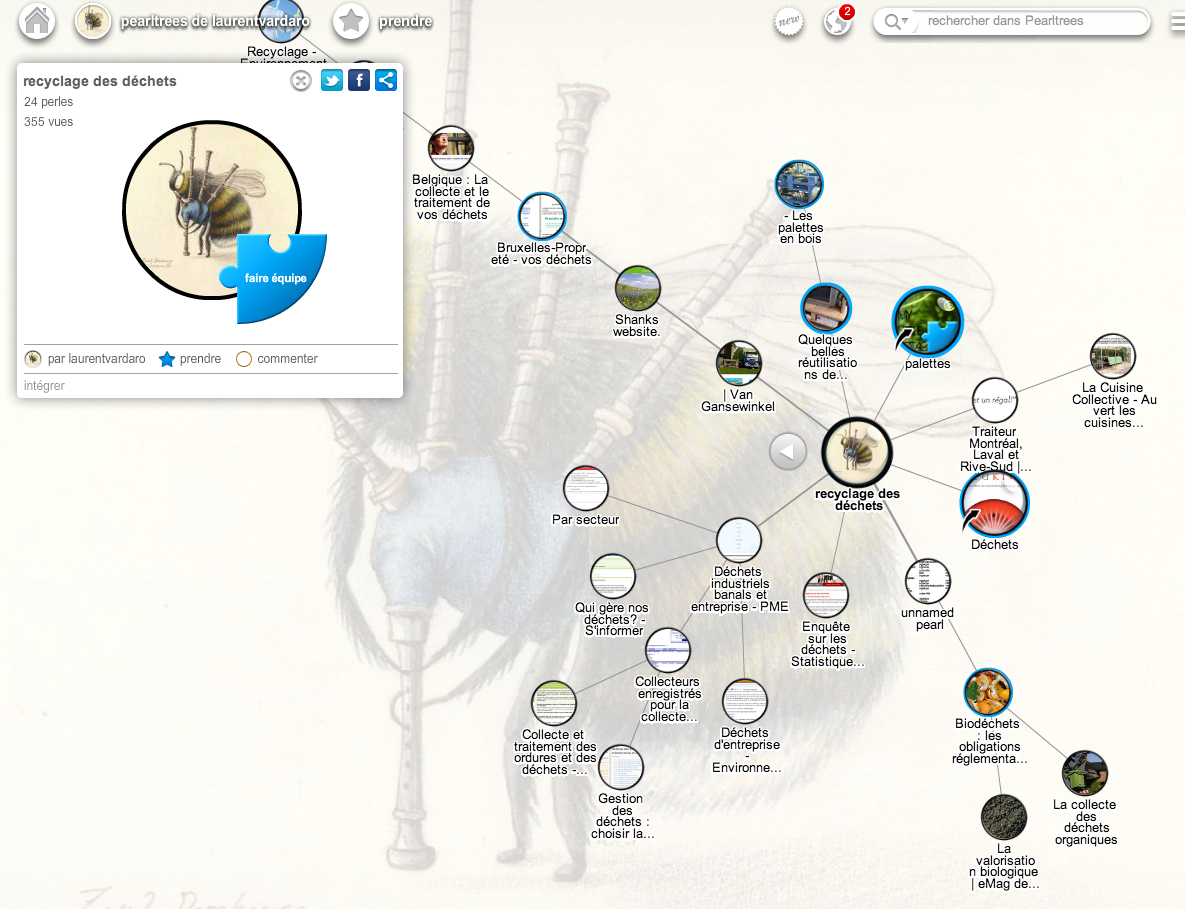
Une recherche sur Google avec la requête gestion déchets site:pearltrees.com permet d’identifier aisément de nombreux pearltrees souvent pertinents, sans qu’il soit nécessaire d’être inscrit au site.
Lorsque l’on a identifié un pearltree, on conseillera d’utiliser la fonction “pearltrees voisins” (onglet en haut de la page), qui affiche alors d’autres pealtrees similaires, la sélection étant basée sur l’analyse des perles communes.
Avec plus de 500 millions de tweets échangés chaque jour, Twitter est aujourd’hui un outil indispensable pour le veilleur.
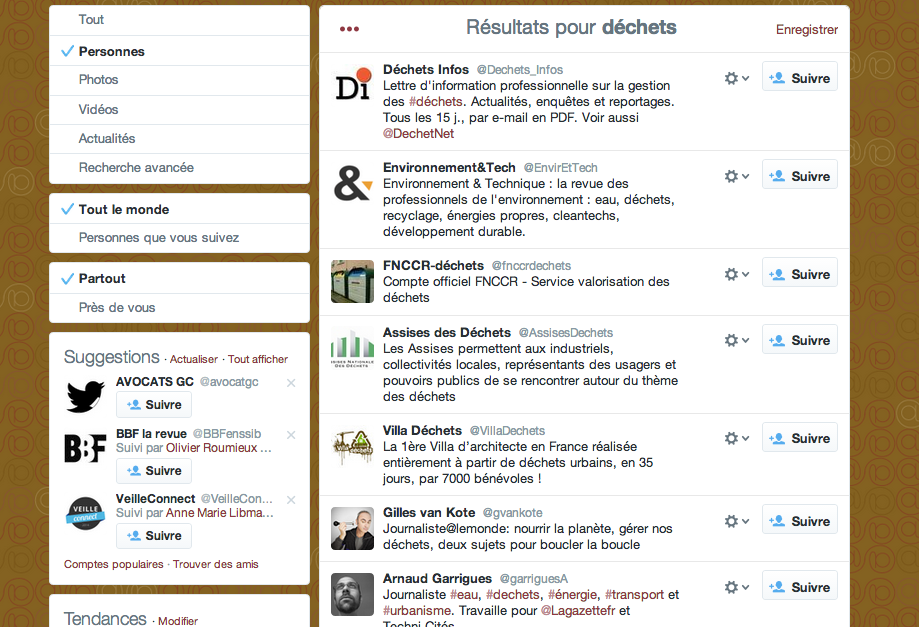
Une requête avec le simple mot “déchets” permet d’identifier les comptes de nombreux twitteurs spécialisés sur cette thématique, parmi lesquels on trouve, par exemple :
- @Dechets_infos : une lettre d’information professionnelle sur la gestion des déchets
- @EnvirEtTech : la revue des professionnels de l’environnement : eau, déchets, recyclage…
- @gvankote : journaliste du Monde spécialisé sur le sujet
- @Ecologic_France : éco-organisme agréé pour la gestion du recyclage des Déchets d’Equipements Electriques et Electroniques (DEEE) ; etc.
On pourra aussi analyser les abonnements suivis par ces professionnels, et se constituer aisément une liste de comptes twitter sur le sujet.
A partir de là, différents outils pourront être utilisés pour suivre, grâce aux fils RSS, les nouveaux tweets publiés par des comptes twitteurs, des listes, ou en réponse à une requête par mots-clés (voir “Panoplie d’outils pour les twitteurs, Netsources n°104”).
Scoop.it
Lancé en 2010, Scoop.it est sans doute la plateforme de “curation” la plus utilisée, que ce soit pour diffuser les résultats de sa veille ou pour suivre l’actualité d’un domaine (voir Netsources n°89). Sa convivialité et son ergonomie en font un outil précieux pour le veilleur, d’autant qu’il est possible de suivre les “scoops” publiés sur le “topic” d’un utilisateur via un fil RSS.
Ces exemples sont donnés à titre d’illustration. Mais d’autres pistes pourraient encore être explorées.
On peut en effet tenter d’identifier spécifiquement des annuaires professionnels (comme l’annuaire des prestataires déchets en Ile de France, proposé par la CCIIdF), des signets de Delicious (tels celui de l’infothèque SIAAP…), des portails Netvibes, des groupes Linkedin ou Viadeo (groupe “Collecte et gestion des déchets” de Viadeo…), etc.
L’essentiel est de garder en mémoire que pour étoffer un sourcing, il faut identifier des “sources”, et non des pages web … et que pour cela, d’autres outils peuvent s’avérer plus performants qu’un moteur, fût-il Google !
Béatrice Foenix-Riou
Publié dans le n°108 de NETSOURCES (Janvier-Février 2014)






